April 03, 2026
API Design: REST, GraphQL, and gRPC
Caching compressed the database load. But components still need a contract for communication. Three styles dominate modern API design, and each makes different trade-offs on flexibility, performance, and tooling.
Caching compresses database load. The redundant, layered architecture that now handles large request volumes still requires every component to communicate. When a web server calls a user service, when a mobile app requests a product listing, when a recommendation engine asks for follower data, something has to define what can be asked and what shape the answer takes. That definition is the API (Application Programming Interface): a contract between two systems specifying what requests are valid, what parameters they accept, and what responses they produce.
Three styles dominate modern system design. REST, GraphQL, and gRPC each solve the same underlying problem but make different trade-offs around flexibility, performance, and tooling. Understanding their differences makes it possible to choose the right one for each use case rather than applying one style across an entire system.
REST
REST (Representational State Transfer) is the most widely used API style. It models the system as a collection of resources. Each resource is a business entity: a user, an order, a product. Resources are identified by URLs using nouns. /users/42 identifies a specific user. /orders identifies the orders collection.
HTTP methods define what operation to perform on a resource. GET reads without modifying state and is idempotent: calling it ten times produces the same result as calling it once. POST creates a new resource. PUT replaces a resource entirely. PATCH modifies specific fields. DELETE removes a resource. The mapping aligns with CRUD (Create, Read, Update, Delete) in a way that HTTP infrastructure, tools, and developers already understand.
REST is stateless. The server holds no session state between requests. Every request carries all the information needed to process it: authentication credentials, query parameters, request body. No session is stored on the server. This is not a limitation. It is the property that makes REST servers horizontally scalable: any server in the pool can handle any request from any client because no request depends on what the previous request left behind.
Every endpoint returns a fixed response shape. A GET to /users/42 always returns the same fields. The client cannot request fewer fields to reduce payload size, and it cannot request related data in the same call. This leads to two common failure modes. Over-fetching occurs when the client needs three fields but the endpoint returns twenty. Under-fetching occurs when the client must make several sequential calls to assemble the data it needs.
API versioning in REST is handled through URL prefixes. /api/v1/users and /api/v2/users coexist, and breaking changes ship in a new version. HTTP caching integrates naturally. GET responses carry Cache-Control headers. Varnish, CDNs, and browsers cache them without any modification to application code.
GraphQL
GraphQL, developed at Facebook and open-sourced in 2015, inverts the REST model. Instead of the server defining a fixed response shape for each endpoint, the client specifies exactly what fields it needs in a query language.
A single endpoint, typically /graphql, handles all operations. The client sends a query describing the exact shape of the response it wants:
query {
user(id: 42) {
name
email
posts {
title
publishedAt
}
}
}
The server returns precisely those fields and no others. Over-fetching is eliminated: the response contains only what was requested. Under-fetching is eliminated: nested data resolves in a single request instead of multiple sequential calls.
GraphQL defines three operation types. A query reads data without side effects. A mutation writes data (create, update, delete). A subscription establishes a persistent connection that pushes data to the client when specified events occur, enabling real-time updates without polling.
Schema evolution works without URL versioning. Deprecated fields remain available while new fields are added alongside them. Clients using old fields continue to work. Clients adopting new fields opt in at their own pace.
The N+1 problem is GraphQL's most common failure mode. Consider a query that returns ten users and includes their posts. The users resolver makes one database query to fetch the ten users. For each user, the posts resolver makes a separate database query. Ten users produce ten post queries: one for the list, plus one per user for posts. That is N+1 queries against the database where two would suffice. At a thousand users, it is a thousand queries where one batch would do the same work.
The standard solution is DataLoader, a utility that batches sub-queries across a single execution cycle. Instead of executing one query per user, DataLoader collects all pending user IDs and issues a single SELECT * FROM posts WHERE user_id IN (…) query. N+1 becomes two queries regardless of list size.
HTTP caching is harder with GraphQL. REST GET requests have stable URLs that map directly to cache keys. GraphQL typically uses POST for all operations, including reads. The query body varies with each client request, so standard Cache-Control caching cannot construct a stable cache key from a dynamic POST body. CDN and Varnish caching do not apply to GraphQL traffic the way they apply to REST. Caching in GraphQL requires application-level solutions: persisted queries with stable GET URLs, or response caching at the resolver level.
gRPC
gRPC is an open-source RPC (Remote Procedure Call) framework developed by Google. Where REST models communication as HTTP requests to resources and GraphQL models it as queries against a schema, gRPC models it as direct function calls between services.
The interface is defined in a .proto file using Protocol Buffers, a binary serialization format. The schema is strongly typed and shared between client and server:
service UserService {
rpc GetUser (UserRequest) returns (UserResponse);
rpc StreamUserActivity (UserRequest) returns (stream ActivityEvent);
}
Code generation tools produce client and server stubs in multiple languages from the same .proto definition. The client calls userService.getUser(request) as a local function. Serialization, transport, and deserialization happen transparently.
gRPC uses HTTP/2 as its transport protocol. HTTP/2 enables multiplexing: multiple concurrent request-response cycles share a single connection without blocking each other. HTTP/1.1 responses must be returned in the order requests were sent. A slow response blocks everything behind it in the queue, a problem called head-of-line blocking. Browsers open multiple parallel connections to work around it. HTTP/2 eliminates the problem by tagging each frame with a stream ID, allowing responses to arrive out of order. HTTP/2 also compresses headers, reducing overhead on high-frequency inter-service calls.
Four call types are available. Unary: a single request produces a single response, equivalent to a standard REST call. Server streaming: a single request produces a stream of responses. Client streaming: a stream of requests produces a single response. Bidirectional streaming: both sides send independent streams simultaneously. REST has no equivalent to server and bidirectional streaming within a single connection.
The browser limitation is significant. Browsers do not support the gRPC protocol natively. The binary framing protocol is not exposed to browser JavaScript. gRPC is a server-to-server protocol. Browser clients must use REST or GraphQL. Internal services communicating with each other use gRPC without restriction.
Binary serialization over Protocol Buffers is more compact than JSON. A typical protobuf message is three to ten times smaller than the equivalent JSON representation. For high-frequency inter-service communication, this efficiency accumulates across millions of calls per day.
When to Choose Which
These three styles serve different positions in the architecture, not different preferences.
REST is the standard for public-facing APIs. It works with every HTTP client, every browser, every language. HTTP caching layers integrate without application changes. Standard authentication patterns (OAuth, API keys, JWT) are well-documented. When an API must be consumed by external developers or clients outside the team's control, REST is the default.
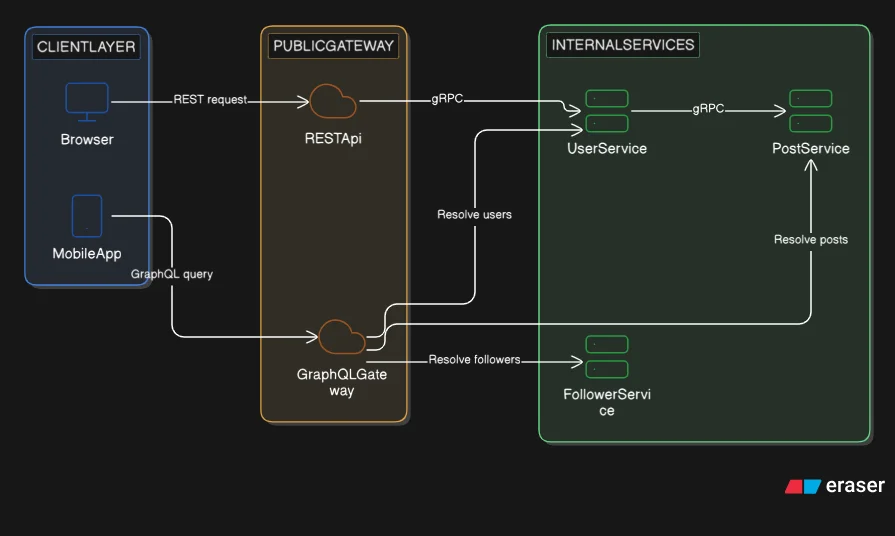
GraphQL fits the aggregation layer, specifically the Backend for Frontend (BFF) pattern. A BFF sits between client applications and the internal service mesh, aggregating data from multiple services into a single client-optimized response. A mobile client and a web client have different data requirements; GraphQL lets each query exactly what it needs. Complex UIs where many page components need different slices of overlapping data are another natural fit.
gRPC fits internal service-to-service communication. When a recommendation service calls a user service, or a checkout service calls an inventory service, gRPC provides stronger typing, better performance, and explicit streaming support. The performance advantage is most meaningful where call frequency is high or where streaming semantics are required.
Takeaways
- An API is a contract between two systems: it defines what operations are valid, what shape requests take, and what shape responses return.
- REST models resources as nouns accessed through HTTP methods. It is stateless, cacheable, and the standard for public-facing APIs.
- GraphQL gives clients control over response shape. It eliminates over-fetching and under-fetching. The N+1 problem occurs when nested resolvers issue one database query per item; DataLoader batches them into a single query.
- HTTP caching works naturally with REST GET requests. GraphQL uses POST by default, which requires application-level caching strategies to achieve equivalent cache coverage.
- gRPC uses Protocol Buffers and HTTP/2. Binary serialization and multiplexed connections make it efficient for internal service communication and streaming. It is not directly accessible from browsers.
- Choose REST for public APIs. Choose GraphQL for aggregation layers serving clients with varied data needs. Choose gRPC for internal services, high-frequency calls, and streaming use cases.
APIs define how components communicate. An open interface is also an open attack surface. The next problem is controlling who can call the API, at what rate, and how to prevent unauthorized access. That is rate limiting and API security.