March 31, 2026
Database Choices: SQL vs NoSQL and When Each Wins
Every system needs a database. The choice between SQL and NoSQL depends on data shape, consistency needs, and scale patterns. We break down both families and give a framework for deciding.
In the previous post, we established the single-server baseline: one machine running the web server, the database, and the cache together. The next question every engineer faces is which database to use.
The choice between SQL and NoSQL is one of the most consequential decisions in system design. It is hard to reverse. Migrating a production database from a relational model to a document store is months of work. Getting it right from the start matters.
In this series, we build progressively. Before we separate the web server from the database, we need to understand what we are working with. Both SQL and NoSQL solve real problems. Neither is universally better. The decision depends on data shape, consistency requirements, and scale patterns.
Two Families
All database systems fall into two families: relational (SQL) and non-relational (NoSQL).
SQL databases organize data into tables with fixed schemas. Each table has columns (attributes) and rows (records). Tables relate to each other through foreign keys (a column in one table that references a specific row in another, linking the two records). PostgreSQL, MySQL, and Oracle are the most widely used examples. The structured query language (SQL) handles all data manipulation.
NoSQL databases reject the fixed-schema table model. They cover four distinct data models: document, key-value, wide-column, and graph. MongoDB, Redis, Cassandra, and Neo4j each represent one of these types. They are not interchangeable. Treating NoSQL as a single category is like treating all SQL databases as identical.
What SQL Gives You
SQL databases are built around a specific set of guarantees called ACID.
Atomicity: a transaction either completes entirely or fails entirely. A bank transfer that debits one account and credits another will not leave the system in a halfway state.
Consistency: every transaction moves the database from one valid state to another. Constraints, foreign keys, and data rules are never violated mid-transaction.
Isolation: concurrent transactions do not interfere with each other. Two users updating the same record do not corrupt each other's writes.
Durability: once a transaction commits, it survives crashes, power failures, and process restarts. The data persists.
These guarantees matter for financial systems, reservations, inventory management, and any domain where data correctness is not negotiable.
Joins let us query across related tables without duplicating data. A customers table, a products table, and an orders table stay normalized (each fact lives in exactly one place, with no repetition across tables). Queries assemble the data at read time. The storage stays clean.
One important clarification: the claim that "NoSQL is faster than SQL" is not accurate as a general statement. For relational workloads with proper indexing, SQL databases are highly competitive. The real performance differences emerge at specific access patterns. A pure in-memory key-value store will always beat a relational database for simple key lookups because it bypasses the query planner entirely and operates from RAM. That is not a SQL weakness. It is a different tool for a different job.
Four Types of NoSQL
NoSQL is not one thing. It is four different data models, each suited to a different problem.
Document stores (MongoDB, CouchDB): data is stored as JSON-like documents. Complex nested structures live in a single record. No joins needed. Well suited for content-heavy applications, product catalogs, and any data with variable structure where the schema evolves over time.
Key-value stores (Redis, Memcached): data is stored as simple pairs, primarily in RAM. Reads and writes are extremely fast. Well suited for session storage, caching, rate limiting counters, and any lookup where raw speed matters more than structure.
Wide-column stores (Cassandra, HBase): data is stored in tables with dynamic columns, partitioned for distributed writes. Well suited for time-series data, IoT event streams, and write-heavy workloads at massive scale.
Graph databases (Neo4j, Amazon Neptune): entities and their relationships are first-class citizens. Traversing connections is fast by design. Well suited for social graphs, recommendation engines, and fraud detection where the relationships between records carry as much meaning as the records themselves.
How to Choose
The core question is: what does the data look like?
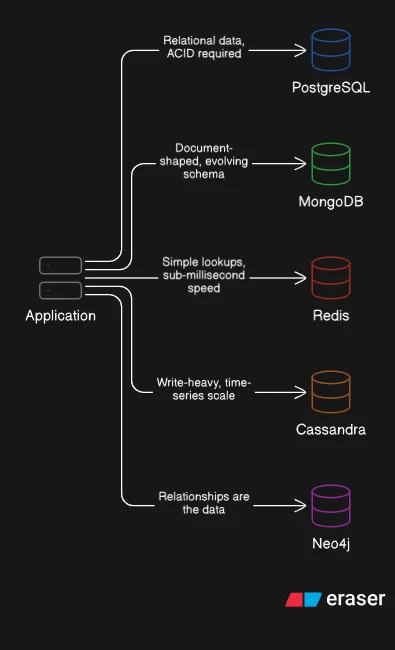
If data has clear relationships and correctness cannot be compromised, use SQL. Financial systems, e-commerce order management, and healthcare records belong in relational databases.
If data is document-shaped and the schema will change as the product evolves, use a document store. User-generated content, product catalogs with varying attributes, and content management systems fit this pattern.
If reads are simple key lookups and speed is the priority, use a key-value store. Sessions, caches, and leaderboards operate in this space.
If writes are the bottleneck and data arrives in time-ordered streams, use a wide-column store. Sensor data, application logs, and event telemetry belong here.
If the connections between entities carry meaning, use a graph database. Fraud detection networks, social graphs, and recommendation systems are built on relationships that SQL joins handle poorly at scale.
One important note: most production systems use more than one database. PostgreSQL handles the source of truth. Redis handles caching. Cassandra handles event ingestion. This is not complexity for its own sake. It is each database doing what it does best. We will see this pattern repeatedly as this series progresses.
Takeaways
The choice is driven by data shape, not trends. SQL is not legacy. NoSQL is not modern. Each fits specific problems. Picking a database because it is popular is how teams end up with the wrong tool for the job.
ACID guarantees are not optional for some domains. For anything involving money, inventory, or order records, consistency is non-negotiable. SQL provides this by default. Reaching those guarantees with NoSQL requires deliberate design effort.
Most systems use more than one database. A single database is a starting point. When we introduce caching layers, event streaming, and search later in this series, each component will bring its own storage model.
We have chosen a database. The web server and database are still on the same machine, competing for CPU and memory. That is the next problem to solve.