April 05, 2026
Database Replication: Read Scaling Through Duplication
A single database node handling millions of reads eventually saturates. Replication copies data across multiple nodes, distributes read load, and introduces consistency trade-offs that every engineer must understand.
The previous post covered security: controlling who can call the API and at what rate. As that API absorbs more authenticated request volume, the database becomes the next constraint. Caching from Post 6 reduces repeated reads by storing answers closer to the application. But caching handles repetition, not sustained volume. When the read workload grows large enough that even cache misses overwhelm a single node, a different mechanism is needed. Replication is that mechanism.
Replication copies data from one database node to one or more additional nodes, then routes read traffic across all of them. The copy operation distributes the load. It also introduces latency, consistency trade-offs, and failure modes that require deliberate handling in application code.
The Master-Replica Pattern
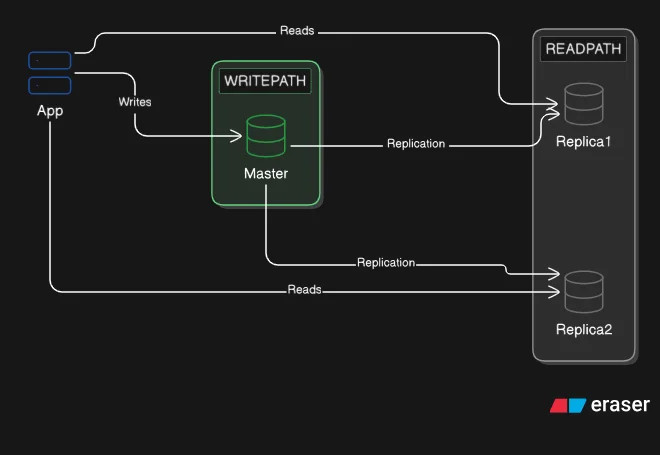
The foundational replication topology has one node that accepts writes and one or more nodes that serve reads.
The node that accepts writes is called the master (or primary). Every INSERT, UPDATE, and DELETE goes to the master. The master records each change and propagates it to the replica nodes. Replicas receive the change stream and apply it to their own copy of the data. Replicas do not accept writes directly: directing a write at a replica is either rejected or produces a divergence that defeats the purpose of replication.
All reads go to replicas. When the application needs to retrieve data, it queries a replica rather than the master. With two replicas receiving the same read traffic, each node handles half the query volume. With four replicas, each handles a quarter. This is the read scaling mechanism: the replica count scales with the read workload, while the master handles writes regardless of how many replicas exist.
Replication Lag and What It Costs
The replication channel between master and replica is not instantaneous. A write acknowledged by the master takes finite time to propagate to each replica. The gap between acknowledgment and replica convergence is called replication lag.
During the lag window, a read from the replica returns stale data. A user submits a form, the write lands on the master, and the immediate page refresh reads from a replica that has not yet received the change. The record appears unchanged. The data is not lost, it has not arrived yet.
This behavior is eventual consistency: the replica will converge to reflect the write, given sufficient propagation time. The system does not guarantee that a replica reflects the most recent state at any given moment, only that it will eventually.
Replication lag is measured in milliseconds for nodes on the same local network under normal load. It can extend to seconds or minutes during heavy write bursts, slow replica hardware, or network interruptions. Monitoring lag is a production responsibility.
Time ─────────────────────────────────────────────────────────────────>
t=0 t=1ms t=40ms t=41ms
| | | |
Write Master Replica Replica
submitted acknowledges receives applies
write change change
from master
During the window [t=1ms, t=41ms]:
- Master: reflects the write
- Replica: still returns the previous value
After t=41ms:
- Both master and replica: consistent
Read-after-write consistency is the specific problem replication lag creates. A user writes data and immediately reads it back. If the read goes to a replica in the lag window, the user sees the pre-write state. The standard handling: any read that must see its own recent write is routed to the master rather than a replica. The application tracks which user actions require this guarantee and selects the appropriate connection accordingly.
Synchronous vs Asynchronous Replication
The timing of propagation is configurable, and the choice controls the trade-off between write latency and data safety.
Asynchronous replication is the default in most databases. The master writes the change to its own storage, acknowledges the write to the caller, and then propagates the change to replicas in the background. Write latency is low because the acknowledgment does not wait for replica confirmation. Replication lag exists and is measurable. If the master fails before propagation completes, the change is acknowledged but not yet on any replica, and those writes are lost.
Synchronous replication requires at least one replica to confirm receipt before the master acknowledges the write. The caller waits for that confirmation. Replication lag is eliminated for the confirming replica: it is guaranteed to have the write at the moment the acknowledgment reaches the caller. The cost is write latency: every write blocks on network round-trip to the replica. If the confirming replica is slow or unavailable, the master stalls. Write availability depends on replica health.
Semi-synchronous replication is the common middle ground. One designated replica must confirm before the master acknowledges. All remaining replicas receive the change asynchronously. One node is guaranteed to have the write; the rest trail by the normal lag. MySQL's semi-synchronous replication plugin and PostgreSQL's synchronous_commit setting implement this model. It provides one guaranteed copy without making write availability dependent on all replicas being healthy.
The choice maps to risk tolerance. Where write durability matters (financial transactions, audit records), synchronous or semi-synchronous replication ensures no acknowledged write is lost on master failure. Where write throughput matters and brief data lag is acceptable (analytics reads, activity feeds, search indexes), asynchronous replication keeps write latency low.
Read/Write Splitting in Application Code
Replication topology has no value unless the application routes traffic correctly. Reads that go to the master do not reduce master load; writes that go to a replica fail or corrupt state.
The implementation requires two connection pools. One pool points at the master and accepts only writes. A second pool distributes connections across replicas, typically through a round-robin or least-connections strategy across the available replica addresses. The application selects the pool based on the operation type.
Most ORM frameworks provide native support. Laravel's database configuration allows separate read and write connection arrays under a single database key. Reads use the read connections; writes use the write connection. The ORM handles pool selection transparently so application code does not branch on operation type in most cases.
The exception is read-after-write. When the application must guarantee that a read reflects a recent write from the same request or user session, that read must go to the master. The application identifies these cases, typically post-submission page loads or confirmation reads, and forces master routing for them. Many frameworks expose a useWritePdo() method or equivalent for exactly this scenario.
A proxy layer such as ProxySQL (MySQL) or Pgpool-II (PostgreSQL) can handle routing at the infrastructure level, keeping the application code unaware of which physical node serves each query. The proxy inspects each statement, identifies reads and writes, and routes accordingly. This centralizes the routing logic and reduces the risk of application-level misrouting.
Failover: Promoting a Replica to Master
The master fails. The application is now writing to a node that is not responding. Reads from replicas continue normally because replicas do not depend on the master for serving queries, only for receiving updates. But writes fail until a new master is available.
Failover is the process of selecting a replica and promoting it to master role. The promoted replica begins accepting writes. All remaining replicas reconfigure themselves to receive changes from the new master rather than the failed one. The application updates its write connection to the new master address.
Manual failover requires an operator to detect the failure, choose the most-current replica, reconfigure it, update replica replication targets, and update the application connection string. This process takes minutes. During that window, writes fail or queue. Manual failover is appropriate for non-critical systems where the operational simplicity of not running orchestration tooling outweighs the downtime risk.
Automatic failover uses an orchestration layer to perform these steps without human intervention. Tools such as MySQL MHA, Orchestrator, Patroni (PostgreSQL), or managed database services such as Amazon RDS Multi-AZ detect master unavailability through health checks, elect the most-current replica, execute the promotion sequence, and update connection routing, typically within tens of seconds to a couple of minutes, depending on the tool and configuration. The application connects to a stable endpoint (a virtual IP or a DNS record) that the orchestration layer updates to point at the new master.
Data loss risk on failover. If replication was asynchronous and the master failed before the most recent writes propagated, those writes existed only on the failed master. The promoted replica does not have them. Recovery from this state depends on whether the failed master is recoverable. If the original master can be brought back online, its more-recent writes can be extracted and applied to the new master before the original is decommissioned. If the original master is unrecoverable, those writes are lost. Semi-synchronous replication limits this risk to the asynchronous replicas: the designated synchronous replica is guaranteed to have all acknowledged writes.
Takeaways
- Replication copies data from a master node to one or more replica nodes. Writes go to the master; reads distribute across replicas. Adding replicas scales read capacity without changing the write path.
- Replication lag is the interval between a write being acknowledged by the master and that write appearing on a replica. During this window, replicas return stale data. This is eventual consistency.
- Asynchronous replication provides low write latency but allows acknowledged writes to be lost on master failure before propagation. Synchronous replication prevents this at the cost of higher write latency. Semi-synchronous replication is the standard middle ground.
- Read/write splitting requires two connection pools: one targeting the master for writes, one targeting replicas for reads. Reads that must reflect a recent write from the same session are routed to the master.
- Failover promotes a replica to master when the current master fails. Automatic failover tools reduce promotion time from minutes to tens of seconds. Asynchronous replication creates a data loss window on failover proportional to the lag at the time of failure.
Replication scales reads by distributing query volume across copies. The master remains the single node accepting all writes. At high write volume, the master itself becomes the bottleneck: no number of read replicas reduces write pressure on the single master node. When write capacity is the constraint, the data must be partitioned across multiple masters. That is what sharding does.