March 25, 2026
Designing a Hotel Booking System: What Makes It Actually Challenging
A high-level walkthrough of the architecture behind a hotel reservation system: the read/write split, concurrency traps, and why it's never just CRUD.
Last week I was booking a hotel for an upcoming trip and found myself thinking: how does this actually work under the hood?
Not the UI. The system. One room left. Hundreds of people looking at it. Two of them clicking Book at exactly the same millisecond. What happens?
That question sent me down a rabbit hole, and this post is the map I drew — or at least the map I think is accurate. No insider access to Booking.com's codebase here, just first principles and educated guesses, so feel free to challenge anything that doesn't add up.
These systems are genuinely challenging. Not because of the feature list, but because of one specific guarantee they have to keep: no two guests should walk up to the same hotel on the same night holding the same reservation. Getting that right at scale is where the interesting architecture decisions live.
Scoping the System
Not all requirements shape the architecture equally. Some just describe features. But a few, once we lock them in, force every other decision.
For this design: search by location, dates, guests and price. Payments on-platform. Cancellations supported. And intentional overbooking of up to 10% (Hotels know from historical data that some bookings cancel before check-in, so they deliberately let a few extra reservations through).
Two non-functional requirements end up driving almost everything:
Write consistency is non-negotiable. Two users cannot book the same room type for the same dates. Period.
Read consistency can be eventual. Search results being a few seconds stale is fine. The only dangerous moment is the booking confirmation itself. That's exactly where we'll focus.
The Numbers Tell Us the Architecture
Before drawing any boxes, let's run through the numbers first.
Booking.com processes around 1.1 billion reservations per year. Divide by average nights per booking (~2) to get actual bookings: ~550 million. Divide by 365 days to get ~1.5 million bookings per day. Divide by 86,400 seconds in a day. That lands at roughly 17 writes per second. Very manageable.
Now the reads: 500 million monthly visitors, each browsing around 8 pages. That's 4 billion page views per month. Divide by 30 days to get ~133 million per day. Divide by 86,400 seconds. That lands at roughly 1,500 read requests per second.
1,500 reads. 17 writes.
That asymmetry is the entire puzzle. The architecture has one job: serve reads at massive scale without letting that scale compromise write consistency. Everything else follows from that.
High-Level Architecture
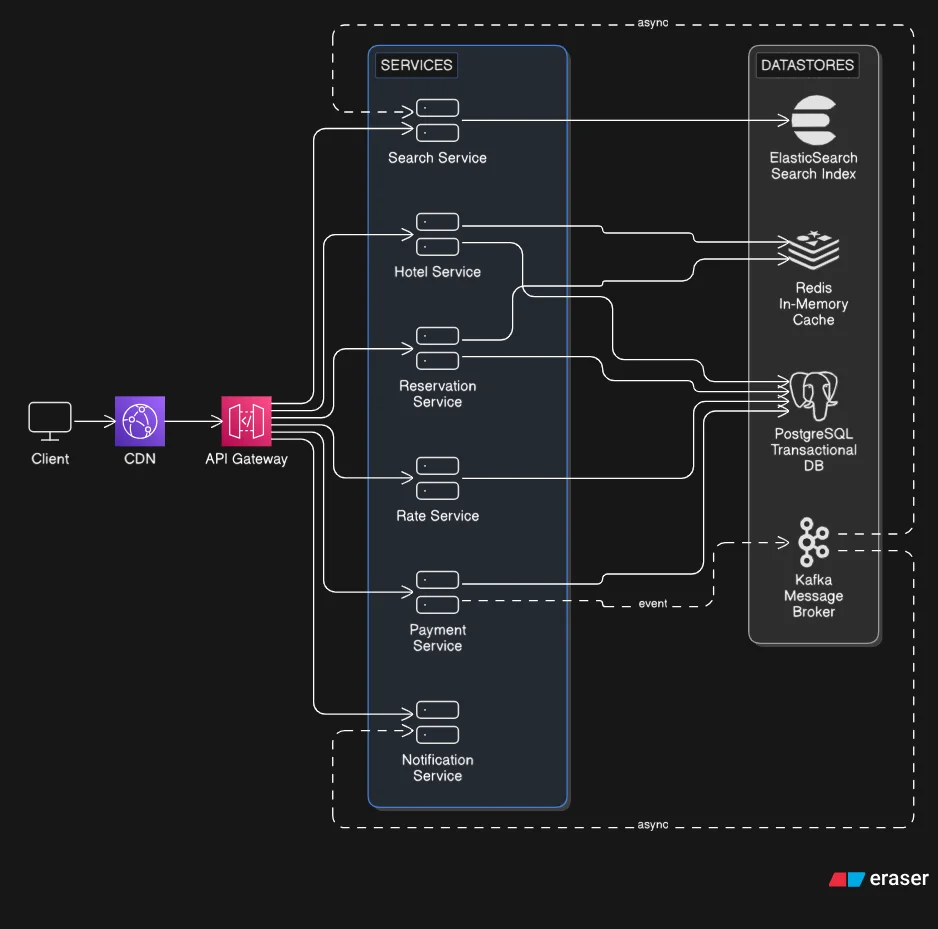
The architecture splits naturally along the read/write divide.
For reads, there's a dedicated Search Service backed by a search index (ElasticSearch). It sits between the API Gateway and the index, owning all query logic: geo-queries (hotels within X km of a location), price filtering, and date availability. A search index handles this workload far faster than a relational database (because it's optimized for text and geo-based queries rather than transactional writes), and it's fine if it's a few seconds behind the source of truth.
Writes go to a transactional database (PostgreSQL), the source of truth for reservations, inventory and transactions. ACID guarantees (Atomicity, Consistency, Isolation, Durability) and complex joins across hotels, room types, inventory, and reservations are where relational databases earn their place.
An in-memory cache (Redis) sits in front of the database for hot, rarely-changing data like hotel details and aggregated availability counts, so we are not hitting the transactional database on every page load.
A message broker (Kafka) is the async glue. When a payment completes, the Payment Service publishes an event. The Notification Service picks it up and sends the confirmation email. The Search Service picks it up and updates the index. Each service does its job independently, without blocking the booking flow.
One deliberate choice worth calling out: Hotel and Reservation data share a single database rather than having separate databases per service.
The case for splitting: true service isolation, independent scaling, and each service owning its data completely. The case against: as soon as Hotel and Reservation data live in separate databases, any operation that touches both requires coordinating a transaction across two separate databases. That's a genuinely hard coordination problem, and it adds complexity that doesn't pay off here given how tightly coupled these two domains are.
Sharing a database means we can use local ACID transactions and keep that complexity out of the application entirely. We still get service-level separation in the code layer. We just accept a tighter coupling at the data layer as the trade-off.
The Reservation Flow
When a user searches, the query goes straight to the search index and comes back fast. After that:
- User selects a hotel, which is fetched from the transactional database to guarantee accurate, up-to-date details
- User submits a booking. The Reservation Service receives the hotel ID, room type, dates, and payment info
- Reservation Service checks inventory against the transactional database
- Payment is charged via the Payment Service
- A message broker event fires. The search index gets updated asynchronously and the confirmation email goes out
There's a brief window after step 4 where the search index might still show the room as available. That's acceptable. If someone tries to book it in that window, step 3 will catch it. Search is eventually consistent. Bookings are not.
The Challenging Part: Preventing Double Bookings
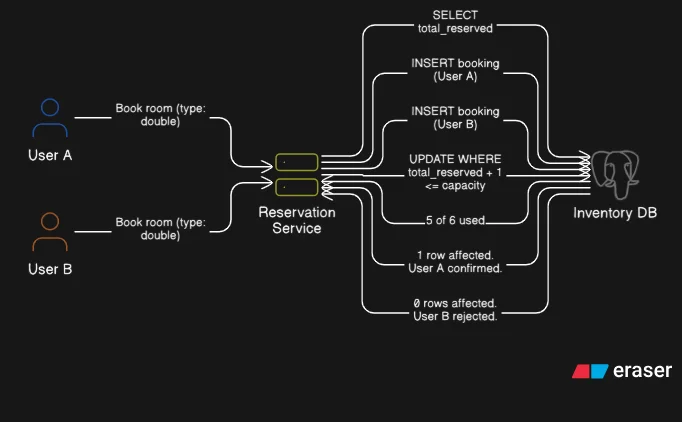
There are two distinct scenarios and they need different fixes.
Scenario 1: the same user double-clicks. When the booking form first loads, a UUID reservation ID is generated and attached to the session. Every submission from that form carries the same ID. If the same ID hits the server twice, the second request finds the reservation already exists and returns it rather than creating a new one. Lightweight and effective for this case.
Scenario 2: two different users, one last room. This is the real problem.
The naive approach is to SELECT the current inventory count, check if a room is available, then INSERT the booking. That's two separate operations with a gap between them. Two users can both run the SELECT at the same millisecond, both see "1 room available," both pass the check, and both proceed to insert. By the time the second write lands, the room is double-booked.
Row-level locking doesn't help here. Both SELECTs already completed before either write begins. The lock comes too late.
The fix is to collapse the check and the write into a single operation. A conditional UPDATE that only succeeds if availability still holds:
UPDATE room_type_inventory
SET total_reserved = total_reserved + 1
WHERE hotel_id = ?
AND room_type_id = ?
AND date BETWEEN ? AND ?
AND (total_reserved + 1) <= total_inventory * 1.10 -- 10% overbooking buffer
Now there is no gap. The condition is evaluated at write time against the live row value. User A's UPDATE commits, incrementing the count. User B's UPDATE runs next, evaluates the same condition against the updated count, fails the condition check, and returns 0 rows affected. One booking confirmed. One clean rejection.
One Schema Detail Worth Understanding
That SQL references a table called room_type_inventory. The name is a clue to an important design decision underneath.
When we book on Booking.com, we are booking a room type (double queen, standard, suite) not a specific room. The actual room number gets assigned at check-in.
Tracking inventory at the type level rather than per physical room is what makes everything else work cleanly. One row per room type per date covers dozens of physical rooms at once. Bulk availability updates, overbooking logic, and dynamic pricing by room type and date all follow naturally from this single choice.
Where This Leaves Us
The interesting part of this system isn't the list of components. It's understanding why each one is there and what we are trading away to use it.
Here the trade-off is deliberate. A transactional database gives us strong write consistency and row-level locking. But it can't carry 1,500 QPS of search reads on its own. So reads get offloaded to a search index that's fast and scalable but accepts being a few seconds behind. We re not trying to make everything consistent. We re deciding exactly where consistency matters and paying that cost only there.
This post covered the high-level picture. Future posts will go deeper into specific parts: the full concurrency handling, database scaling and sharding, caching strategy, and what happens when parts of the system fail under load.