April 02, 2026
Eliminating Single Points of Failure: Redundancy at Every Layer
Every component added to a distributed system creates a new potential single point of failure. The answer is redundancy at every layer, applied consistently across the load balancer, web server, and database tiers.
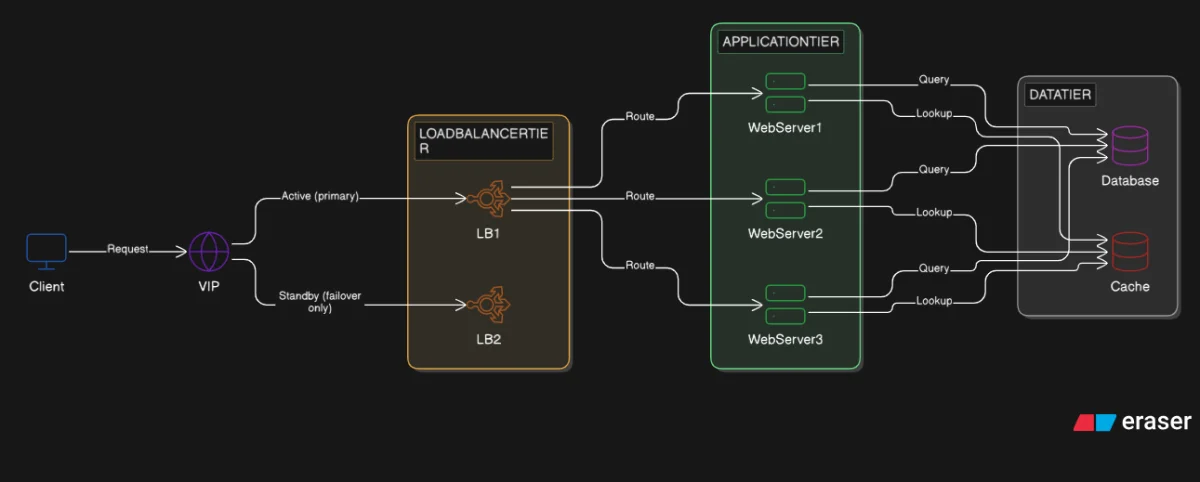
The load balancer solved the web server SPOF. Three web servers now share the load. If one fails, the other two absorb it. The system keeps running.
But we introduced a new problem in the process. All three web servers receive traffic through one load balancer. If the load balancer fails, no request reaches any server. The entire system goes offline, even though the web servers and database are healthy.
This is the expected shape of distributed systems design. Every component we add solves one failure mode and creates a new potential one. The answer is not to stop adding components. The answer is redundancy at every layer.
Where SPOFs Hide
A single point of failure (SPOF) is any component that exists as exactly one instance. One instance means one point of failure. The current architecture has three.
The load balancer. Every request passes through one machine. If it fails, traffic stops before it reaches any web server.
The database. All three web servers read and write through one database instance. If the database fails, all three web servers fail simultaneously, regardless of how healthy they are.
The cache. The cache is less immediately dangerous. When the cache fails, requests fall back to the database. But under real load, this fallback creates a thundering herd: every request that formerly hit the cache now hits the database at once, simultaneously, because there is nothing to absorb them. The database becomes the bottleneck again, rapidly.
The principle is straightforward: any component with one instance is a SPOF. Applying that principle across every tier is the actual work.
Active-Passive vs Active-Active
Two patterns address redundancy. Which one applies depends on whether the component carries state.
Active-passive runs one primary node and one standby. The primary handles all traffic. The standby sits idle. For stateful components, the standby continuously receives replicated data from the primary so it can take over with current data. For stateless components, both nodes carry the same configuration and no data replication is needed. When the primary fails, the standby is promoted (it takes over as the new active node). Promotion takes seconds to minutes. Standby capacity is wasted during normal operation. The advantage: only one node ever accepts writes, so there is no concurrent write coordination between active nodes.
Active-active runs both nodes simultaneously. Both handle traffic. When one fails, the survivor absorbs the full load without a promotion step. No idle capacity. No promotion window. The cost: both nodes must serve consistent data. Writes must coordinate, or routing logic must ensure consistency.
The choice follows one rule.
Stateless components (load balancers and web servers) are candidates for active-active. They carry no user state. Any node can handle any request without coordination.
Stateful components (primarily the database) start with active-passive. The primary node serializes all writes. A replica is promoted when the primary fails. Full active-active for databases requires distributed write coordination, which we will address when the series reaches sharding.
Making the Load Balancer Redundant
Load balancers are stateless, so both active-active and active-passive configurations work. The VIP pattern shown here uses active-passive because it is simpler to operate and reason about. There is no risk of split-brain (two nodes simultaneously believing they are the primary), and no write coordination is required.
We run two load balancer instances. One is primary, one is standby. But there is a coordination problem: the client connects to a domain name. That name resolves to an IP address. If that IP address belongs to one specific machine, the machine itself is still a SPOF.
The solution is a Virtual IP (VIP): a floating IP address that is not tied to any physical machine. DNS resolves the domain to the VIP. A coordinator process manages which load balancer holds the VIP at any moment.
Keepalived is the standard tool for this on Linux. Both load balancer nodes run the Keepalived process. Keepalived on each node sends and listens for periodic heartbeat advertisements. When the secondary stops receiving heartbeats from the primary, it concludes the primary is down, adds the VIP to its own network interface, and broadcasts a gratuitous ARP to notify every device on the network that the VIP now lives on a different machine. This happens within seconds. Clients connect to the VIP. New connections after the failover reach the secondary transparently. TCP connections that were open at the exact moment of failure are dropped, but clients retry automatically. For short-lived HTTP connections to a load balancer, this is imperceptible. No DNS TTL delay (TTL is the duration a DNS response is cached by clients; propagating a DNS change can take minutes to hours as every client cache expires) and no client reconfiguration is required.
This mirrors exactly what the load balancers do for web servers: health checks, automated failure detection, automated failover.
The Database SPOF
The load balancer tier and web server tier are now redundant. The database is still a single node.
Web server redundancy provides no protection when the database fails. All three web servers become unavailable the moment the database goes down, regardless of how many web server instances are running. Horizontal scaling at the web tier does not improve database resilience.
The solution is replication. A primary database node handles all writes. One or more replica nodes maintain synchronized copies and handle reads. When the primary fails, a replica is promoted to primary. This distributes read load and eliminates the single point of failure at the data tier.
Replication introduces consistency constraints, specifically around failover coordination and read-write lag (the delay between a write landing on the primary and appearing on replicas), covered in Post 9. For now, the database SPOF is a named limitation. We accept it at this scale and return to it when data volume and reliability requirements demand it.
CAP Theorem: The Limit of Redundancy
Redundancy means data lives on multiple nodes. That creates a new problem when those nodes lose the ability to communicate. A network partition severs the communication link between nodes. Each node keeps running, but they cannot reach each other.
During a partition, a system faces a choice. Prioritize consistency (the C in CAP): every node returns the same data, but some nodes must refuse to respond until they synchronize with the rest. Prioritize availability (the A in CAP): every node responds immediately, but responses may contain stale data from before the partition.
Both cannot be guaranteed simultaneously when a partition occurs (the P in CAP stands for partition tolerance: the system must keep operating even when nodes cannot communicate). This is the CAP theorem. Every distributed data architecture takes a position on that trade-off. We will apply it directly when the series reaches replication and sharding.
Takeaways
- Any component with one instance is a SPOF. Redundancy at every tier is the only resolution.
- Stateless components are candidates for active-active. Any instance handles any request without coordination.
- Stateful components start with active-passive. State complexity increases with active-active write coordination.
- Virtual IPs decouple the client-facing address from physical machines. Keepalived assigns the VIP automatically on failure.
- Database replication eliminates the data tier SPOF. It is covered in Post 9.
- CAP theorem defines the outer bound: during a network partition, consistency and availability cannot both hold simultaneously.
The architecture now survives individual component failures. But redundant servers reading the same data from the database on every request still creates a bottleneck. Caching is the next move.