April 01, 2026
Load Balancers: Distribute Traffic, Eliminate Bottlenecks
One web server is a single point of failure. Two web servers need a coordinator. The load balancer distributes incoming requests, detects failures, and removes failed servers from rotation automatically.
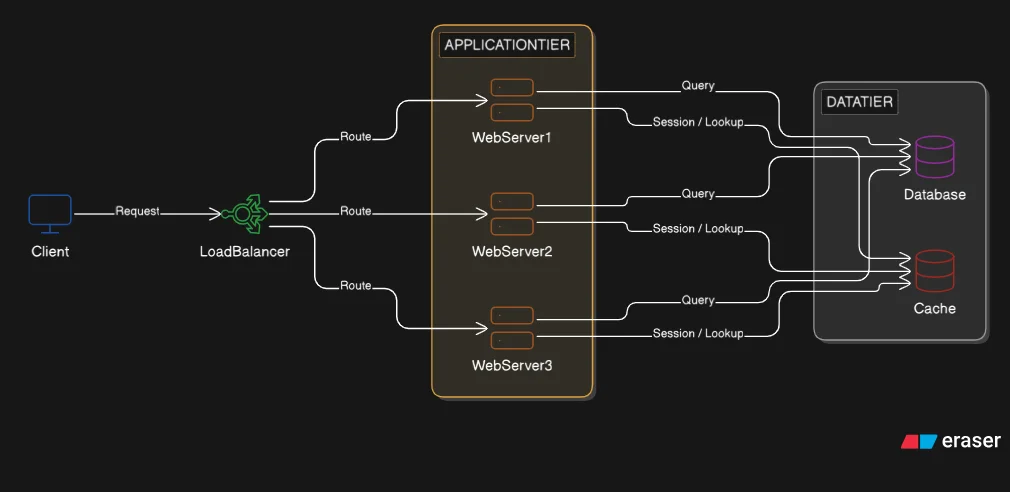
We separated the system into three tiers: web server, database, and cache. Each component now runs on its own machine and can fail independently. But the web server is still a single point of failure. One machine handles every request. If it goes down, the system goes offline.
The fix is horizontal scaling: add more web server instances. Three machines now share the load that one carried before. But a new problem appears immediately. The client sends a request. Which server receives it? There is no component in place to make that decision. We need a coordinator.
That coordinator is the load balancer. It sits between the client and the web server pool, receives every incoming request, and decides which server handles it. It also monitors server health and stops routing to failed servers automatically.
What a Load Balancer Does
A load balancer sits in reverse proxy position. A regular proxy sits in front of clients and forwards their requests outward. A reverse proxy sits in front of servers and accepts requests on their behalf. The load balancer faces the client and proxies requests forward to internal servers. The client connects to the load balancer's address. It never connects directly to a web server. From the client's perspective, there is one server. Behind that address, there are many.
Three responsibilities define the load balancer.
Traffic distribution: every incoming request is routed to one of the available web servers according to a routing algorithm. The load balancer makes this decision on every request.
Health monitoring: the load balancer sends periodic health check requests to each server. If a server does not respond, the load balancer marks it as unavailable and stops sending traffic to it. When the server recovers and health checks succeed again, it re-enters the rotation.
Automatic failover: because health checking is continuous, server failures are detected within seconds. Traffic shifts to the remaining healthy servers without any manual intervention. No single web server is a SPOF anymore.
How Distribution Works
The load balancer needs a rule for deciding which server receives each request. There are several routing algorithms, each with a different trade-off.
Round-robin is the simplest. Requests are distributed in a fixed rotating sequence: first request to Server 1, second to Server 2, third to Server 3, fourth back to Server 1, and so on. This works well when all servers have identical specifications and requests take roughly the same time to process. When those conditions do not hold, round-robin breaks down: a slow request on Server 1 accumulates backlog while Server 2 sits idle.
Least connections routes each new request to the server with the fewest active connections at that moment. If Server 1 has 10 active connections, Server 2 has 9, and Server 3 has 30, the next request goes to Server 2. This is better suited to workloads where requests vary in duration. An API call that computes a report may hold a connection for several seconds. A simple lookup takes milliseconds. Least connections accounts for that imbalance; round-robin ignores it.
IP hash uses a hash of the client's IP address to determine the destination server. The same client IP always hashes to the same server. This is called session affinity or sticky sessions. It solves a real problem, which we cover in the next section. The trade-off: if one IP generates disproportionate traffic, that server absorbs more load than the others. Distribution becomes uneven.
Two other algorithms exist and are worth naming. Weighted variants assign higher traffic share to servers with greater capacity (more RAM, more CPU). Geographical routing routes clients to the server closest to their physical location, reducing latency for globally distributed systems. Both are appropriate at larger scale; round-robin and least connections cover most applications.
Sessions and Statefulness
Post 3 stated that the application tier is stateless by design. This deserves a precise definition, because it is not always what it sounds like.
Stateless means no user session data lives on the web server between requests. It does not mean the server has no process state at all. The distinction matters when adding a load balancer.
Many applications write session data to local memory or to a file on disk. This was invisible with a single server: the same machine handled every request from the same user and always found its own session data. With two servers behind a round-robin load balancer, user A logs in on request 1, which lands on Server 1. Session data is written to Server 1's memory. Request 2 from the same user lands on Server 2. Server 2 has no session data for this user. The result: the user appears logged out.
One response is to use IP hash and send each client's requests to the same server always. This is sticky sessions. It solves the immediate symptom. It introduces two problems. First, fault tolerance breaks: if Server 1 goes down, all users whose sessions live on Server 1 lose their sessions. Second, load distribution becomes uneven as different clients generate different traffic volumes.
The correct solution is to externalize session state. Session data is written to a shared data store that all web servers can read and write. Redis, already sitting on the data tier from Post 3, handles this role exactly. Every web server reads the session from Redis at the start of a request and writes any changes back at the end. The server that handles request 1 does not need to be the same server that handles request 2. Any server can continue any session because the session lives in a shared store, not in any server's memory.
This is what stateless by design means in practice: the application tier holds no state that is not also in the data tier. The load balancer can now route freely using round-robin or least connections, with full fault tolerance restored.
What This Introduces
The load balancer is now a required component for every request. All traffic passes through it. If the load balancer fails, all traffic stops. We solved the web server SPOF, but we introduced a new SPOF at a different layer.
This is a consistent pattern in distributed systems: solving one single point of failure reveals the next. Eliminating SPOFs at every layer is the subject of the next post.
Takeaways
Load balancers distribute traffic and detect failures automatically. Health checks run continuously. A failed server is removed from rotation within seconds. The remaining servers absorb the traffic without manual intervention.
Algorithm choice depends on workload characteristics. Round-robin works when servers are identical and requests are uniform. Least connections handles variable-duration requests better. IP hash provides session affinity at the cost of uneven distribution and weaker fault tolerance.
Stateless application servers require externalized session state. Sessions written to local server memory break under round-robin distribution. The solution is external session storage: Redis on the data tier. Any server can then handle any request without affinity requirements.
The load balancer distributes traffic effectively. But the load balancer itself is now a single point of failure. Eliminating SPOFs at every layer is the next problem to solve.