April 01, 2026
Separation of Concerns: Web Server, Database, and Cache
Running everything on one machine is simple until it is slow. The first real scaling move is separation: give each component its own server so each can fail and scale independently.
We have a database selected. The web server and database are still on the same machine, competing for CPU and memory. That is the problem this post solves.
The fix is separation. We move each component to its own dedicated server: the web server runs on one machine, the database runs on another, the cache runs on a third. This is not complexity for its own sake. It is the only architecture that lets each component fail and scale independently.
This is the first real scaling move in the series. Everything before this was design and configuration. This is the first time the infrastructure physically changes.
Why One Machine Fails
In the single-server setup, the web server, database, and cache share the same CPU and memory pool. There is no isolation between them.
Resource contention is the immediate problem. A slow database query consumes CPU cycles that the web server needs to handle incoming requests. A spike in web traffic consumes memory that the database needs for query caching. The two workloads interfere with each other constantly because they share the same hardware.
There is no fault boundary. If the database process crashes, the web server process keeps running. But every request that requires a database query returns an error. From the user's perspective, the service is down. If the web server exhausts available RAM, the database has less memory for its own query cache and slows down. A failure in any component degrades every other component, because all of them draw from the same shared pool of CPU, RAM, and disk on one machine.
Independent scaling is impossible. If the database needs more RAM to handle query volume, we must upgrade the entire machine. The web server gets more RAM too, whether it needs it or not. We pay for resources the wrong tier consumes. And vertical scaling (upgrading the machine's CPU, RAM, and disk) has a hard ceiling. There is a physical and financial limit to how much a single machine can grow.
Separation addresses all three of these problems at once.
Three Tiers
Once we separate components, the system has a clear three-tier structure.
Presentation tier: the clients. Web browsers and mobile apps. These are outside the system boundary. We do not own or operate them. They initiate requests and consume responses.
Application tier: the web server. This machine handles business logic, request routing, authentication, and API response formatting. It is stateless by design: it does not store any user-specific data between requests. Every request arrives as if it is the first. No session data, no persistent state lives on this machine. A stateless application tier is what makes horizontal scaling possible later. Any instance can handle any request, because no instance holds data the others do not have.
Data tier: the database and cache. These are the only machines that hold state. The database server handles persistent reads and writes. The cache server handles fast in-memory lookups for data that does not change frequently.
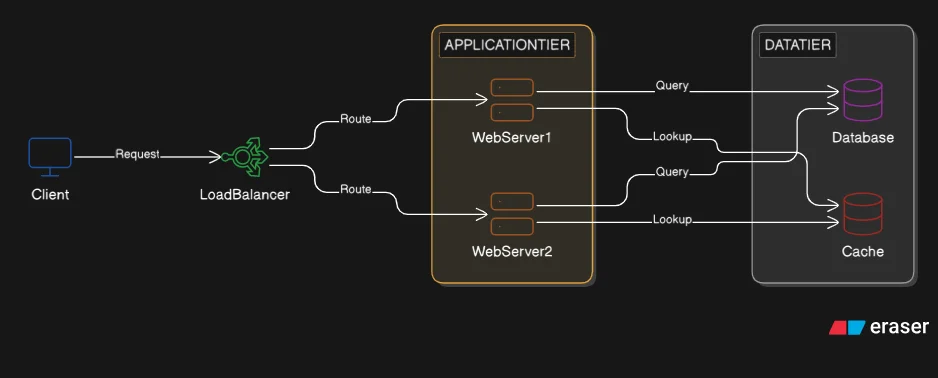
Note the cache position here. In the first post, the cache ran in-process on the single server: Redis or Memcached on localhost, sharing the same machine as the web server. That was a convenience of the single-server setup. In the separated architecture, the cache becomes a dedicated server in the data tier: the same Redis node that Post 2 described as handling session storage and caching. That pattern now has physical form.
Scaling Each Tier
With three tiers separated, we can scale each one based on its own load profile. This is the architectural shift that makes scaling decisions precise.
Vertical scaling means adding resources to a single machine: more CPU, more RAM, faster disk. It is simple to implement. No application changes needed. For the database tier in particular, vertical scaling is often the first move: a database server with more RAM can cache more query results in memory, reducing disk reads dramatically.
Vertical scaling has a ceiling. Price increases non-linearly as machines get larger, and there is a physical limit to the RAM and CPU available in a single server.
Horizontal scaling means adding more machines of the same type to share the load. No hard ceiling. Each machine added increases capacity linearly. Horizontal scaling also introduces redundancy: if one machine fails, the others continue serving traffic.
The application tier is the easiest to scale horizontally. Because it is stateless, any web server instance can handle any request. We can add two, three, or twenty web server instances and they all behave identically.
Horizontal scaling of the web tier requires something to distribute incoming traffic across multiple instances. A single entry point must decide which server receives each request. That component is a load balancer, and it is the subject of the next post.
What Separation Introduces
Separation is not free. There is one tradeoff worth naming.
On a single machine, the web server connects to the database over a Unix socket, bypassing the TCP/IP network stack entirely. On separated servers, every database query is a network call. This adds latency and introduces connection overhead.
Connection pooling manages this cost. Instead of opening a new TCP connection to the database for every incoming request, the application tier maintains a pool of pre-established connections that are reused. The overhead of connection setup happens once at startup, not once per request. Most application frameworks (Laravel, Django, Rails, Spring) manage connection pools automatically.
One concern emerges when the web tier scales horizontally: each web server instance maintains its own independent pool. With ten web servers each holding a pool of twenty connections, the database receives two hundred simultaneous connections. Databases have a hard limit on this count. At that point, an external connection pooler (PgBouncer for PostgreSQL, ProxySQL for MySQL) sits in front of the database and multiplexes all those pools into a bounded number of real connections. Multiplexing here means many application connections share a smaller set of actual database connections: the pooler accepts two hundred incoming connections but holds only twenty open connections to the database, routing requests through whichever connection is free. That is a later problem. At this scale, framework-managed pooling is sufficient.
Takeaways
Separation enables independent scaling. The database tier and application tier have different resource profiles. Separating them means each can be sized and scaled according to its own demand, not the other tier's.
Each tier now has its own failure boundary. A database crash no longer brings down the web server. A web server memory leak no longer starves the database. Component boundaries are now enforced by separate operating system processes on separate machines.
Connection pooling manages the network overhead, with a caveat. The cost of a network hop between tiers is real but small. Connection pooling makes it a one-time cost at startup, not a per-request penalty. Under horizontal scaling, each web server adds its own pool to the total database connection count. An external pooler handles this at scale.
Three servers, three tiers. But if the web server machine fails, every request fails with it. That single point of failure is the next problem to solve.