March 31, 2026
Single-Server Architecture: The Web Foundation
Backend systems are complex, with components acting at different layers. We start simple: one machine running everything. Understanding this baseline is the foundation for everything that follows.
Backend systems are complex. Many components (HTTP servers, storage systems, load balancers) act at different layers: application layer, network layer, transport layer.
In this series of posts, we will go through all of that progressively. But we start simple: a single-server architecture, where everything runs on one machine: the web server, the database, the cache.
This is not the architecture we use at scale. It is the architecture we need to understand before the rest makes sense. When engineers talk about distributed systems, replication, and caching layers, they are solving problems that only exist because this simple setup reached its limits.
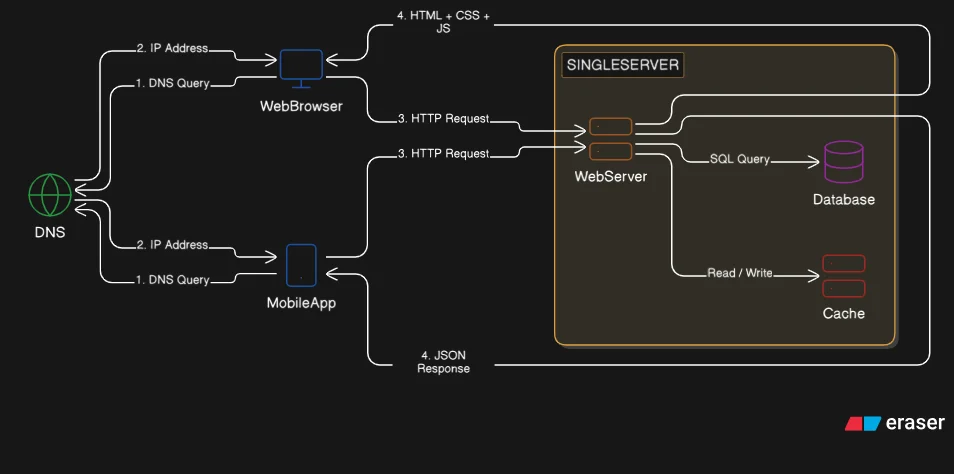
The Single Server Setup
In the beginning, everything runs on one machine. The web server, the database, the cache. All competing for the same CPU, memory, and disk.
This setup handles requests from two types of clients: web browsers and mobile apps. Browsers get HTML, CSS, and JavaScript. Mobile apps get JSON over HTTP. Same server, different response formats.
For a small user base, this works perfectly. No distributed system complexity. No network calls between components. No synchronization problems. Just one machine handling requests and querying the database locally.
There is no resource isolation between components. Each runs as a separate OS process, but all share the same pool of CPU, memory, and disk. A memory leak in the database shrinks the RAM available to the web server. A CPU spike in one component starves the others. Everything competes because there is only one pool of resources.
The simplicity is the point. We are not optimizing for scale yet. We are proving the concept works.
How Requests Flow
Users do not connect to IP addresses directly. They type domains. That is where DNS comes in.
Here is the flow from domain to response: the client types a domain, the OS contacts a DNS server which returns the matching IP address, the client sends an HTTP request to that IP, and the server returns a response.
DNS is a lookup table. Domain in, IP address out. Once the client has the IP, it sends an HTTP request directly to the server.
The server receives the request, runs business logic, queries the database if needed, and returns a response. For web traffic, that is a full HTML page with assets. For mobile traffic, that is JSON data the app can render.
This request/response cycle is identical whether we are serving one user or a million. The mechanics do not change. Only the infrastructure around it does.
Web vs Mobile Traffic
Two types of clients reach the server, each expecting different things.
Web browsers need the full stack. The server handles business logic, data access, and presentation. It returns HTML rendered on the server, along with CSS and JavaScript for interactivity. The browser receives everything it needs to display the page.
Mobile apps follow a different pattern. They request raw data over HTTP using API calls. The server responds with JSON. The app handles its own presentation layer. The server only provides data.
Here is what a typical mobile API call looks like:
GET /api/products/12345
Response:
{
"id": 12345,
"name": "Wireless Keyboard",
"description": "Mechanical switches, 60% layout",
"price": 79.99,
"in_stock": true
}
Same server. Same business logic. Two different output formats. The server does not care if the request came from Safari or an Android app. It processes the request and returns what was asked for.
Why This Works (And When It Does Not)
This architecture works when traffic is low and occasional downtime is acceptable. One server is easy to reason about. No network latency between components. No data synchronization. No distributed transactions.
But it breaks under three conditions.
First: Resource contention. The web server and database compete for CPU and memory on the same machine. A slow database query blocks web requests. A spike in web traffic starves the database. Everything interferes with everything else because there is no isolation.
Second: Single point of failure. If the server crashes, everything stops. No redundancy. No failover. One hardware failure takes down the entire system.
Third: No independent scaling. We cannot scale the database separately from the web tier. If the database needs more memory but the web server does not, we are forced to upgrade the entire machine. Vertical scaling works for a while, but it is expensive and has hard limits.
The limitation that matters most: database queries and web requests competing for resources on one machine. That is the first thing to fix.
Takeaways
Start simple. Understanding how a single server works clarifies what all the advanced patterns are actually solving. Distributed systems are answers to questions this architecture cannot handle.
Request flow is foundational. DNS resolution, HTTP requests, server processing, database queries, and responses. This sequence does not change when we scale. We just add layers around it.
Web and mobile have different demands. Browsers need rendered pages. Mobile apps need raw data. Same business logic, different serialization.
Limitations drive architecture. This setup works until resource contention, single points of failure, or scaling constraints force us to separate components. That separation is what we address next.
A single-server architecture is one machine doing everything. When resource contention becomes the bottleneck, we separate components. That is next.